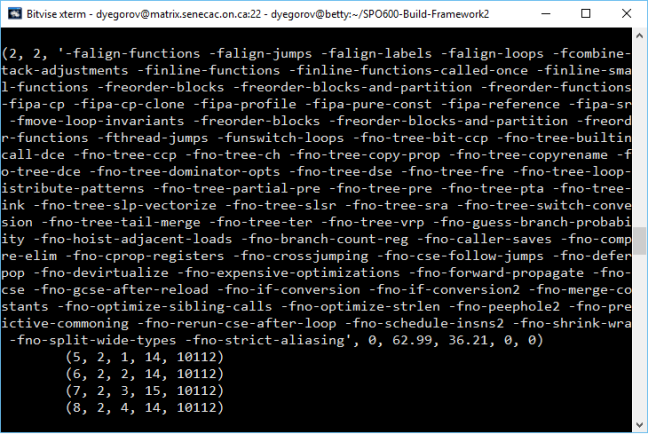
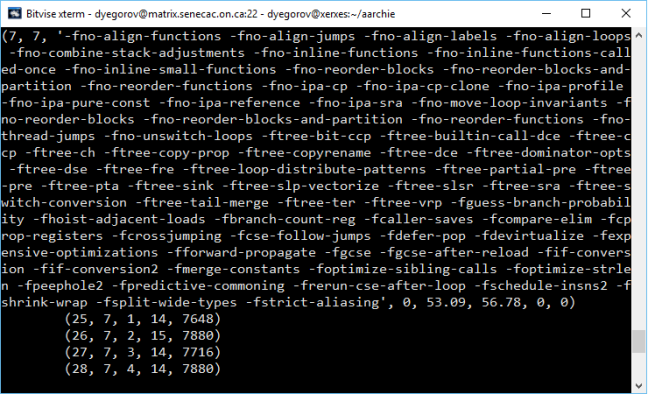
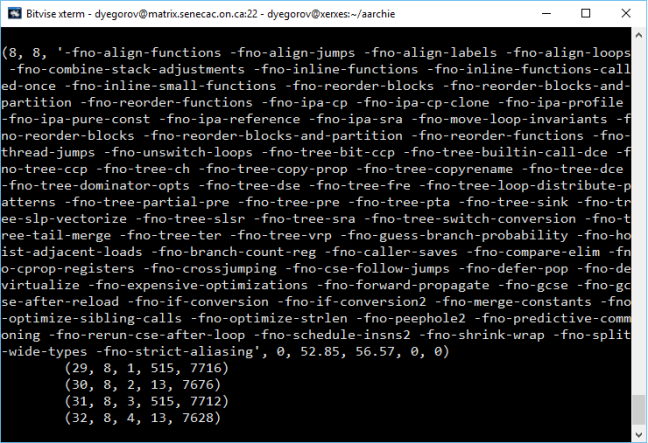
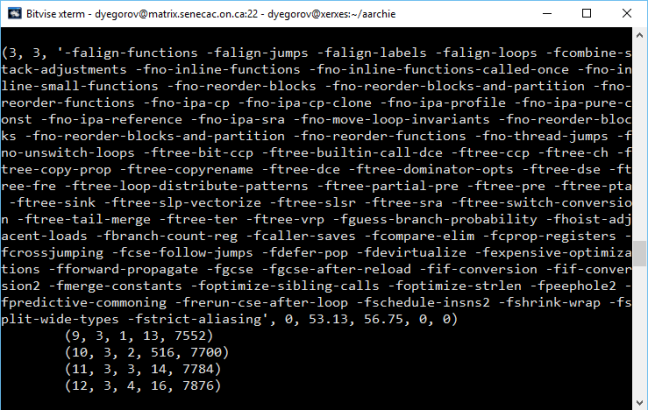
So this semester I had a pleasure taking SPO600 that was about software portability and optimization. In other words, if you have a piece of software, this course would teach you how to make this software work, work with increased performance and in different environments (CPU architecture, system requirements etc). I would consider this course as something that lies between programming and what is know by the term IT – you do not create software, but you work with the code using some hardware specific methods.
During this course I learned about CPUs, how they work, how to make them perform specific instruction, how to program on CPU level and so on. I already knew about CPUs, different processor architectures, but my knowledge was very basic, and now I got a chance to learn in-depth about it and apply my knowledge in practice.
I really liked how this course was structured, as there were, pretty much, no obligations, due dates or whatsoever – it was very informal and friendly, which makes this course different (in a good way for sure) from any other courses I’ve had in Seneca. Also, we got introduced to Open Source community and were provided with lots of opportunities to visit different events, such as FSOSS and X-Windows conference – another way to get in touch with Open Source communities and meet many interesting people. The only downside of this course was that some questions in quizzes we had were pretty unexpected, and when the professor was answering those questions, you would sit like “What is this? I see it for the first time”. However, if you look at “Additional materials” links at the bottom of each week’s wiki-page, you would find many useful resources and everything gets clear after that. Also, even if you did not know answers for some questions, you still could use logic, and based on the knowledge you already had, guess the right answer – for me it worked 90% of the time 🙂
Another thing why I found this course very useful for myself was that I am looking for the job exactly in this field. I do like to work with code, but I am not that kind of person who can spend 10 hours a day (and more) writing this code; at the same time, I do not feel like working in Tech. Support and System Administration, and this course deals with issues that lie exactly somewhere between these two areas. This course’s topic is exactly what I’d like to be doing in my workplace. Hopefully, I will be able to find this kind of job soon.
It was exciting adventure taking this course, and very useful one for sure. I would definitely recommend this course to people that want to understand how exactly processors work and get to know low-level programming.
Cheers!